Ready for another dive? Today we’ll be exploring a vital component in building today’s powerful LLMs, playing a significant role in RAG systems.
DATA SCIENCE
NLP
Author
Naomi Lago
Published
May 1, 2024
Extracting and normalizing content from a diverse document types - like images, PDFs, PowerPoints, Word, etc., is a crucial step extensively used in RAG systems to enhance their performance by ensuring that the information fed into them is not only relevant but also contextually rich and well structured. By diving into this text, we’ll explore how this preprocessing step can be done using an API to set up a pipeline that handles three types of documents: Images, PDFs, and HTML.
In the field of information processing and retrieval, the ability to extract, normalize, and structure content from various document types is essential for Retrieved-Augmented Generation (RAG) systems, requiring specialized methods for extraction and normalization of each type. Before we dive into the main goal of this dive, let’s first make a clear difference among LLMs, Fine-Tuning, and RAGs - which are things that people still mix up a bit.
Fine-Tuning vs RAG
Before getting to know more about each particularity between these two concepts, let’s state that Large Language Models (LLMs) are pre-trained models on vast datasets, enabling them to understand language structure, context, and semantics. They are foundation for both Fine-Tuning and RAG, offering a broad understanding of language - hence they can be fine-tuned for specific tasks or combined with RAG to enhance their performance.
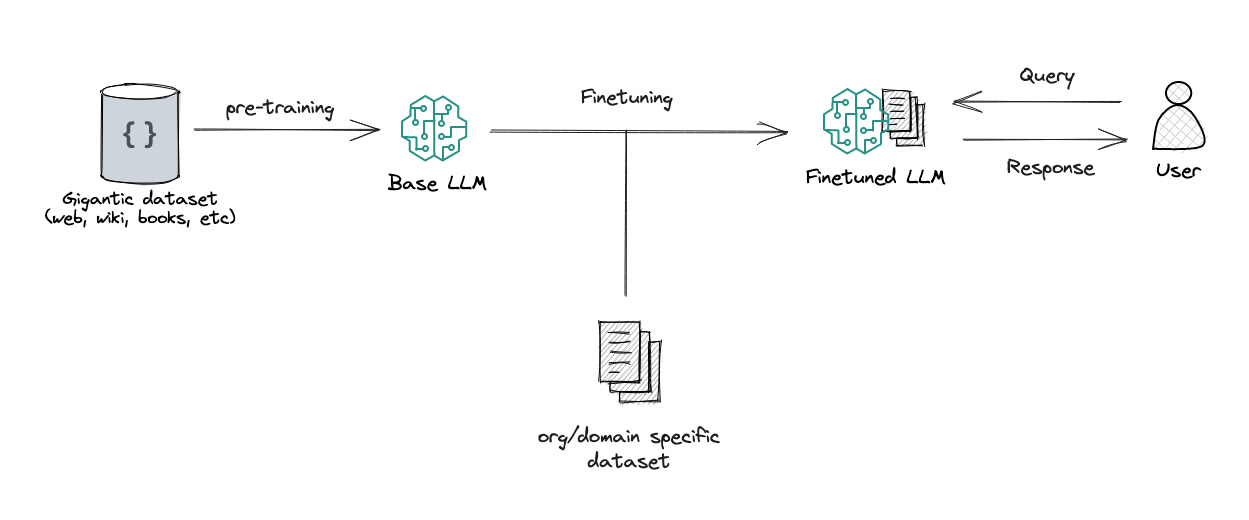
When talking about Fine-Tuning, we’re talking about adapting an LLM behavior, writing style, or domain-specific knowledge to specific nuances, tones, or terminologies. It is particularly effective for achieving a deep alignment with vocabulary and conventions, making it ideal for specialized applications requiring high expertise. Hence, it is best when seeking to tailor the outputs closely to specific requirements and having extensive specific data.
Fine-tuning workflow
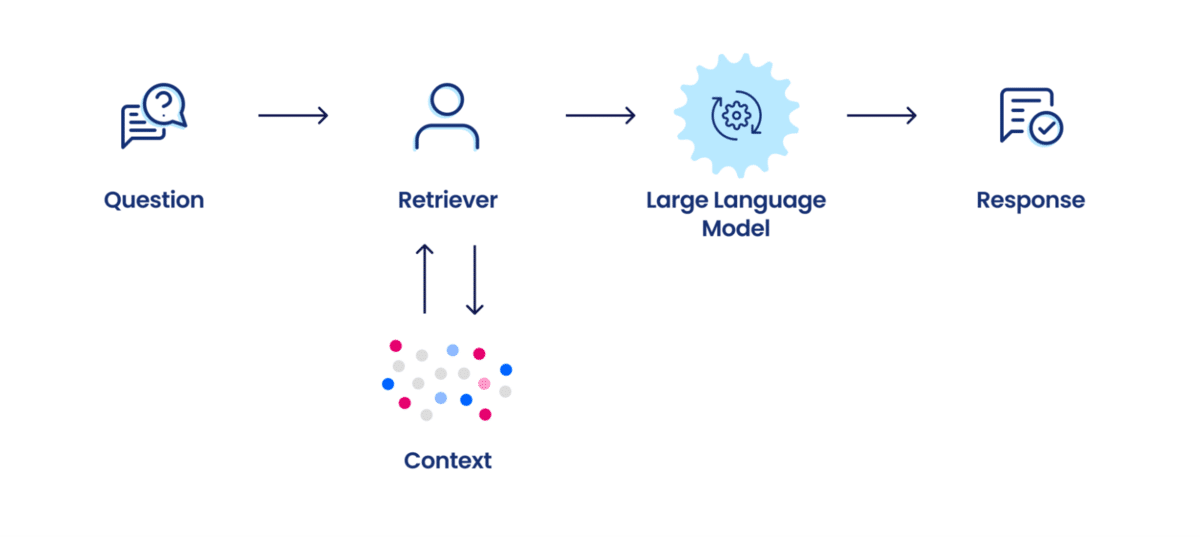
Now RAG, in other hand, focus on enhancing LLMs by connecting them to external knowledge sources through retrieval mechanisms - excelling at incorporating dynamic external data, making it suitable for scenarios requiring up-to-date information or where context is crucial. It offers transparency in response generation by breaking down the process into distinct stages, which is beneficial for applications where interpretability is a priority.
RAG workflow
Unstructured API
Now, let’s talk about the solution we’re exploring today: the Unstructured API - a powerful tool that provides advanced document understanding and preprocessing capabilities, enabling RAG systems to better retrieve abd generate information from a wide range of document types across various domains. I’ve chosen this service because it offers a comprehensive set of features that can be easily integrated into existing pipelines, it’s used by leaders in AI such as Weaviate, LangChain, Yurts AI, etc., but most importantly, it has a free API for study purposes.
Unstructured
For further guidance on how to install and set up your environment, please refer to their documentation.
Preprocessing a PowerPoint file
Alright, now let’s get a feel of how we can use the API on a PowerPoint file. Now, using a sample file I made on how to multiply matrices, I’ll import the necessary modules, read the secrets, and partition the file.
[<unstructured.documents.elements.PageBreak at 0x196b15facb0>,
<unstructured.documents.elements.Title at 0x196b15f9120>,
<unstructured.documents.elements.NarrativeText at 0x196b15f91e0>]
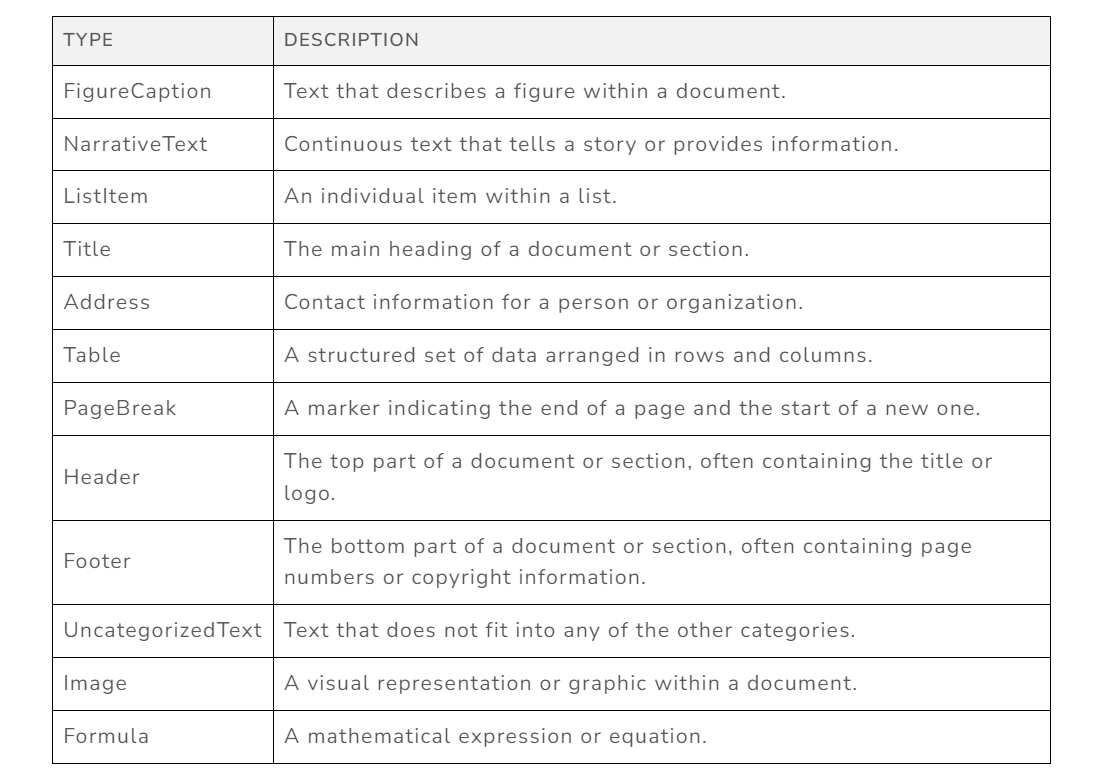
We can see that it’s pretty much it! We get a response from the API with a a list of Unstructured elements - which already spoils us that there are things related to page breaks, titles and narrative texts. Before seeing this result more clearly, refer to this table of available types of elements that can be processed:
Element types
Finally, let’s print the content of an element to see what we got here:
print(json.dumps(res[4].to_dict(), indent=2))
{
"type": "NarrativeText",
"element_id": "d7eb94d4cac7d41d58597655b1da567c",
"text": "Not every pair of matrices can be multiplied. If you have two matrices, the number of columns in the first matrix MUST equal the number of rows in the second matrix",
"metadata": {
"category_depth": 0,
"page_number": 2,
"languages": [
"eng"
],
"parent_id": "5bc89aa807bab5a1ab4499371c48d959",
"filetype": "application/vnd.openxmlformats-officedocument.presentationml.presentation"
}
}
By transforming into a Python dictionary, we can see some valuable information:
type: The element type (referred from the table above).
element_id: A unique identifier for the document element.
text: The actual content or text of the element, if any.
metadata: Additional information about the element, divided into:
page_number: The page number where the document is located.
languages: A sequence of language codes indicated the languages used in the element.
parent_id: The identifier of the parent element, if any.
filetype: The element’s MIME type, indicating the file format.
How about we apply some conditions to gather what we are looking for? Maybe some e-mail, or even an element talking about the impossibility of multiplying some matrices?
# Trying to find an e-mail, if any.result = [elem for elem in res if elem.to_dict()['type'] =='EmailAddress']iflen(result) >0: print(f'Found {len(result)} e-mail address elements! \n')print(json.dumps(result[0].to_dict(), indent=2))
# Trying to find something about the impossibility of multiplying matrices.from pprint import pprintresult = [elem for elem in res if'cannot be multiplied'in elem.to_dict()['text'].lower()]iflen(result) >0: print(f'''Found {len(result)} result on page { result[0].to_dict()["metadata"]["page_number"]}! \n''')pprint(result[0].to_dict()['text'], width=132)
Found 1 result on page 4!
('On the other hand, a 5 x 2 matrix cannot be multiplied by another 5 x 2 matrix even though they both have the same dimensions. '
'Here is a visual representation:')
Alright, alright! This was funny but still hard coded as the search for a specific case for matrices multiplication was matched exactly with our query. Maybe in the future we can dive into embeddings, and join knowledges from the vector databases that I talked in some of the previous dives we’ve had, such as:
Now, let’s make something more fun: modules. With them, we can package code into functional units, making it easier to understand, maintain, and reuse.
Defining the core components
Before making the main agnostic function, that will be the module that preprocess files whether they are Images, PDFs, or HTML, we need to look into these individual components to check if there’s any particular need, as well as also build a core function for its type.
Image component
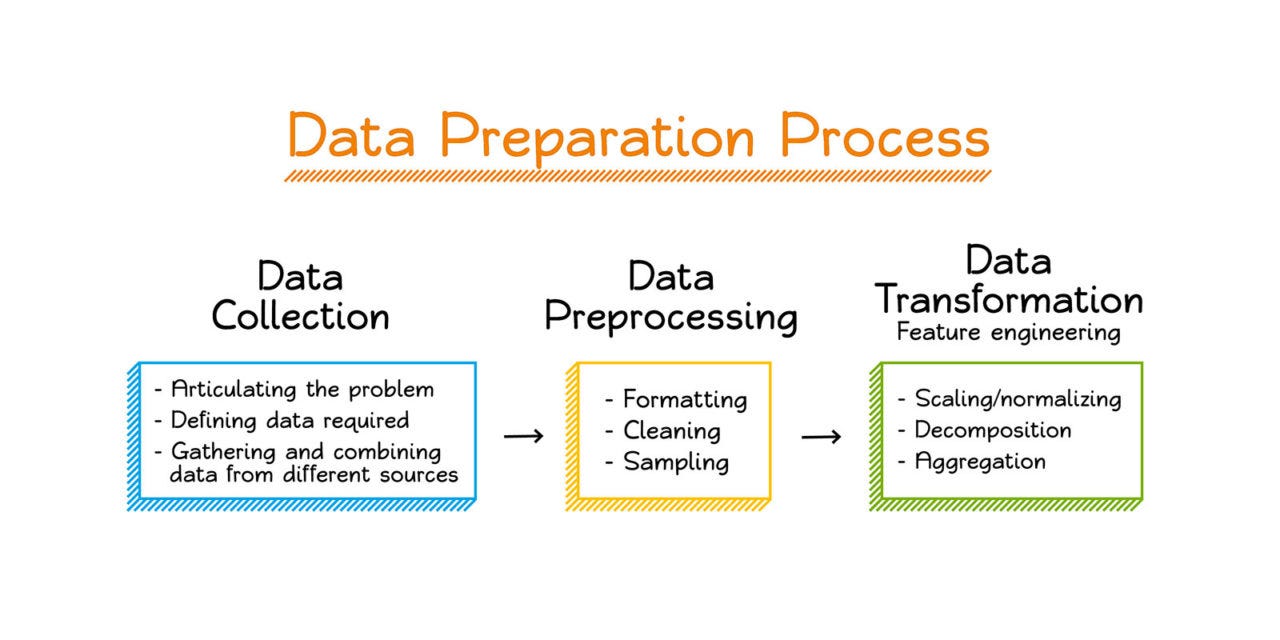
The first I’ll do is an image preprocessor - that uses this image below as a sample, but can be used with any other image files.
Sample image
from unstructured_client import sharedpath ='./data-preparation-process.jpg'req = shared.PartitionParameters( files=shared.Files( content=open(path, 'rb').read(), file_name=path ))res = s.general.partition(req)[_ for _ in res.elements if _['type'] =='ListItem'][:2]
def image_handler( path: str, client: UnstructuredClient, verbose: bool=False ) ->list[dict]:''' Handles images and returns a list of elements from the Unstructured API. Parameters: path (str, required): A valid path to an image file. client (UnstructuredClient, required): An instance of the UnstructuredClient class. verbose (bool, optional): Whether to log the process and its results. Returns: list[dict]: A list of dictionary elements from the API. '''if verbose: logger.info('Partitioning the image parameters...') req = shared.PartitionParameters( files=shared.Files( content=open(path, 'rb').read(), file_name=path ) )if verbose: logger.info('Sending the request to the API...') res = client.general.partition(req)if verbose: logger.success('The image was successfully partitioned! \n')returnlist(res.elements)
res = image_handler( path='./badminton.png', client=s, verbose=True)logger.info(f'The partitioned Image has {len(res):,} elements!')res[3:4]
2024-05-01 19:10:56.231 | INFO | __main__:image_handler:19 - Partitioning the image parameters...
2024-05-01 19:10:56.232 | INFO | __main__:image_handler:28 - Sending the request to the API...
2024-05-01 19:11:00.598 | SUCCESS | __main__:image_handler:32 - The image was successfully partitioned!
2024-05-01 19:11:00.599 | INFO | __main__:<module>:7 - The partitioned Image has 16 elements!
[{'type': 'NarrativeText',
'element_id': 'a9e65672c3378de02797f52e2b127f79',
'text': 'WHAT DO WE KNOW ABOUT BADMINTON? It 1s a racket sport played using rackets to hit a shuttlecock across a net',
'metadata': {'filetype': 'image/png',
'languages': ['eng'],
'page_number': 1,
'parent_id': '1ea170c90190d980e2355ac3f4d4bbb4',
'filename': 'badminton.png'}}]
In the above code, I first tried outside of any function just to make sure I was using the right imports - needing to also use the shared module from the client in order to partition the parameters and then pass into the client API. Finally, I turned it into a function component, containing a docstring and loggers for further documentation and debugging.
PDF component
Now it’s time for the PDF component - one of the most common type of unstructured data used for this purpose. As I’m a real passionate about Deep Learning, I’ll be using the famous open-source Dive into Deep Learning book that can be found here.
NOTE: Since the book has +1k pages, it can take a while to process it all with the free API.
def pdf_handler( path: str, client: UnstructuredClient, verbose: bool=False ) ->list[dict]:''' Handles PDFs and returns a list of elements from the Unstructured API. Parameters: path (str, required): A valid path to a PDF file. client (UnstructuredClient, required): An instance of the UnstructuredClient class. verbose (bool, optional): Whether to log the process and its results. Returns: list[dict]: A list of dictionary elements from the API. '''if verbose: logger.info('Partitioning the PDF parameters...') req = shared.PartitionParameters( files=shared.Files( content=open(path, 'rb').read(), file_name=path ) )if verbose: logger.info('Sending the request to the API...') res = client.general.partition(req)if verbose: logger.success('The PDF was successfully partitioned! \n')returnlist(res.elements)
res = pdf_handler( path='./dive-into-deep-learning.pdf', client=s, verbose=True)logger.info(f'The partitioned PDF has {len(res):,} elements!')[_ for _ in res if _['type'] =='ListItem'][5:6]
2024-05-01 19:11:00.637 | INFO | __main__:pdf_handler:19 - Partitioning the PDF parameters...
2024-05-01 19:11:00.653 | INFO | __main__:pdf_handler:28 - Sending the request to the API...
2024-05-01 19:14:59.602 | SUCCESS | __main__:pdf_handler:32 - The PDF was successfully partitioned!
2024-05-01 19:14:59.609 | INFO | __main__:<module>:7 - The partitioned PDF has 23,042 elements!
[{'type': 'ListItem',
'element_id': '60de89542339e0337ca6cfbd58127812',
'text': '3. Tweak the knobs to make the model perform better as assessed on those examples.',
'metadata': {'languages': ['eng'],
'page_number': 44,
'parent_id': 'b605350bc00209520b7cd8f546322663',
'filename': 'dive-into-deep-learning.pdf',
'filetype': 'application/pdf'}}]
HTML component
Finally, we can make our HTML component handler. For this, I’ll use a sample from the own Unstructured documentation welcome page.
from unstructured.partition.html import partition_htmldef html_handler( path: str, verbose: bool=False ) ->list[dict]:''' Handles HTMLs and returns a list of elements from the Unstructured API. Parameters: path (str, required): A valid path to an HTML file. verbose (bool, optional): Whether to log the process and its results. Returns: list[dict]: A list of dictionary elements from the API. '''if verbose: logger.info('Partitioning the HTML content...') res = [_.to_dict() for _ in partition_html(file=open(path, 'rb'))]if verbose: logger.success('The HTML was successfully partitioned! \n')return res
res = html_handler( path='./unstructured-documentation.html', verbose=True)logger.info(f'The partitioned HTML has {len(res):,} elements!')[_ for _ in res if _['type'] =='ListItem'][0]
2024-05-01 19:14:59.645 | INFO | __main__:html_handler:19 - Partitioning the HTML content...
2024-05-01 19:14:59.744 | SUCCESS | __main__:html_handler:23 - The HTML was successfully partitioned!
2024-05-01 19:14:59.749 | INFO | __main__:<module>:6 - The partitioned HTML has 27 elements!
Last but not least, we can create our main agnostic function that will be able to handle all the types of files we’ve seen above, and will be the one that could be used to preprocess these data.
NOTE: These file extensions are just examples, and you can use any other type of file that the API supports. For a complete list of supported file types, please refer to the documentation.
def data_preprocessor( path: str, type: str, client: UnstructuredClient, verbose: bool=True ) ->list[dict]:''' Preprocesses unstructured data and returns a list of elements from the Unstructured API. Parameters: path (str, required): A valid path to an HTML file. type (str, required): The type of the unstructured data. client (UnstructuredClient, required): An instance of the UnstructuredClient class. verbose (bool, optional): Whether to log the process and its results. Returns: list[dict]: A list of dictionary elements from the API. '''ifstr.lower(type) in {'image', 'pdf', 'html'}:ifstr.lower(type) =='image':if verbose: logger.info(f'Processing an image...')return image_handler(path=path, client=client, verbose=verbose)elifstr.lower(type) =='pdf':if verbose: logger.info(f'Processing a PDF...')return pdf_handler(path=path, client=client, verbose=verbose)elifstr.lower(type) =='html':if verbose: logger.info(f'Processing an HTML...')return html_handler(path=path, verbose=verbose)else:if verbose: logger.error(f'{str.upper(type)} is not a currently supported file!')raiseSystemError
That’s pretty amuch it, and now we can test it out on other files - to make sure it works well on a variety of files within our list of possible extensions.
2024-05-01 19:14:59.783 | INFO | __main__:data_preprocessor:22 - Processing an image...
2024-05-01 19:14:59.784 | INFO | __main__:image_handler:19 - Partitioning the image parameters...
2024-05-01 19:14:59.784 | INFO | __main__:image_handler:28 - Sending the request to the API...
2024-05-01 19:15:02.577 | SUCCESS | __main__:image_handler:32 - The image was successfully partitioned!
2024-05-01 19:15:02.578 | INFO | __main__:data_preprocessor:25 - Processing a PDF...
2024-05-01 19:15:02.579 | INFO | __main__:pdf_handler:19 - Partitioning the PDF parameters...
2024-05-01 19:15:02.580 | INFO | __main__:pdf_handler:28 - Sending the request to the API...
2024-05-01 19:15:03.094 | SUCCESS | __main__:pdf_handler:32 - The PDF was successfully partitioned!
2024-05-01 19:15:03.095 | INFO | __main__:data_preprocessor:28 - Processing an HTML...
2024-05-01 19:15:03.095 | INFO | __main__:html_handler:19 - Partitioning the HTML content...
2024-05-01 19:15:03.341 | SUCCESS | __main__:html_handler:23 - The HTML was successfully partitioned!
image_res[4]
{'type': 'Image',
'element_id': '2634c3dd82e6aad631e772d02e4c46ef',
'text': 'How might | prepare for What skills may be necessary? this career? -Build a writing portfolio Strong writing skills Good interviewing skills -Practice writing by doing unpaid or freelance worl Ability to explain math and science in simple language',
'metadata': {'filetype': 'image/png',
'languages': ['eng'],
'page_number': 1,
'filename': 'technical-writer.png'}}
pdf_res[3]
{'type': 'NarrativeText',
'element_id': '49f8e5d385825f66d315ece00dc9f77a',
'text': '“Snow White”’s historical credentials are well known: as the Disney studio’s first feature-length film, it marked a significant turning point for Walt Disney himself, for the Disney studio, for the art of anima- tion, and to some extent for American films in gen- eral. Like most celebrated “firsts,” it wasn’t really the first animated feature. But it’s fair to say that no earli- er feature had showcased the full range of animation technique in the way that “Snow White” did, nor so combined it with rich color, an infectious musical score, and an absorbing, carefully developed story. Instead of creating an art-house curio, bidding for attention on its novelty value alone, Walt boldly jumped into the center of the arena, crafting an ani- mated feature that could compete with the major stu- dios’ live-action features on their own terms. The sheer audacity of this concept in 1937 is impressive enough, but Walt didn’t stop with the concept. So fully did “Snow White” realize its goals that it scored a spectacular worldwide success at the box office, forcing the rest of the film industry to pay attention, and forever changing the course of the Disney stu- dio.',
'metadata': {'languages': ['eng'],
'page_number': 1,
'parent_id': 'd7452354e7eacad5675c5086fe277cc9',
'filename': 'snow-white-and-the-seven-dwarfs.pdf',
'filetype': 'application/pdf'}}
html_res[-51]
{'type': 'NarrativeText',
'element_id': 'dd03218422acdfe04a165e071f121caf',
'text': 'Os cinquenta mil manifestantes escutaram então os discursos de vários líderes social-democratas e liberais, entre os quais August Palm e Hjalmar Branting.[13]',
'metadata': {'emphasized_text_contents': ['[', ']'],
'emphasized_text_tags': ['span', 'span'],
'link_texts': ['August Palm', 'Hjalmar Branting', None],
'link_urls': ['/wiki/August_Palm',
'/wiki/Hjalmar_Branting',
'#cite_note-forstamaj-13'],
'page_number': 1,
'languages': ['por'],
'parent_id': 'b4b4563a9eb59295e2032feb8d15ae05',
'filetype': 'text/html'}}
Yay! We got our agnostic function ready-to-use. I also made sure to include another language (portuguese) in the HTML content to remember that the Unstructured services handles different languages very well, and the content itself is related to the International Workers’ Day that is celebrated today.
Next Steps
Before we finish today’s dive, I would like to talk about the next steps that could be followed after this preprocessing - such as connecting to a vector database, generating embeddings to feed RAG systems, or even fine-tune some LLMs around this world. For these cases, chunking is also an important thing and using parents’ information within each element is also very useful for making a strong knowledge base. Now, let’s see the next steps that could be undertaken post-processing:
Connecting to a Vector Database: After preprocessing, the data is prepared for efficient storage and retrieval. A vector database is crucial for managing these embeddings, facilitating quick and accurate information retrieval.
Generating Embeddings for RAG Systems: The preprocessed data is transformed into embeddings, which are semantically rich representations. These embeddings are vital for understanding the context and relevance of the information within the RAG system.
Fine-Tuning Large Language Models (LLMs): With the embeddings generated and stored in the vector database, the next step involves fine-tuning LLMs. This process enhances the model’s ability to generate coherent and contextually accurate responses to user queries.
Each of these plays a pivotal role in the overall process, contributing to the development of a robust and efficient information retrieval and generation system. By following these steps, we can leverage the power of preprocessing, vector databases, embeddings, and LLMs to create a comprehensive solution for handling and processing large volumes of data.
Conclusion
What a dive, huh?! We started by understanding the difference between Fine-Tuning and RAG systems, then talked about this amazing service called Unstructured as a powerful tool for advanced document preprocessing and understanding. With the practical examples, we could see, through demonstrations, how to handle different file types using their API - using a modular approach for efficient content extraction and setting the stage for further enhancements.
Looking ahead, we can already outline potential next steps that are essential for enhancing these systems’ performance, enabling them to retrieve and generate contextually rich responses from a vast array of data sources. Personally, I love Information Retrieval, so I would be really glad to bring one or two of these steps in a future dive - so, stay tuned :)
Thanks for reading, I’ll see you in the next one ⭐