%pip install faiss-gpu -UqqNote: you may need to restart the kernel to use updated packages.In the last article, I talked about information retrieval with Vector Search, and one of the technologies I mentioned was the FAISS library from Facebook. It’s an open-source library for efficient similarity search and clustering of dense vectors.
In the last article, I talked about information retrieval with Vector Search, and one of the technologies I mentioned was the FAISS library from Facebook. It’s an open-source library for efficient similarity search and clustering of dense vectors. Today, let’s explore an implementation of this masterpiece on a set of texts - exemplifying, but not limiting, the use of this tool that can bring excellent results.
Well, as I said, we will talk about FAISS - which stands for Facebook AI Similarity Search. This is a technology developed by Facebook’s Artificial Intelligence Research team (FAIR) and was released in March 2017. It is delivered in the form of a Python library and designed to be efficient in searching for and retrieving similar vectors in large datasets, making it very useful in recommendation systems, computer vision, natural language processing (NLP), or anomaly detection.
FAISS offers a wide range of indexing methods, including exhaustive search, k-means, product quantization, and HNSW. These methods enable faster and more accurate searches, even in high-dimensional spaces.
Below, we can observe a representation of how this works under the hood. After indexing our vectorized training data, we can perform searches with new vectors that will use cosine distance, inner product, or L2 distance for the search, which then gives us an output in ascending order with the smallest similarities (indicating they are close and related).
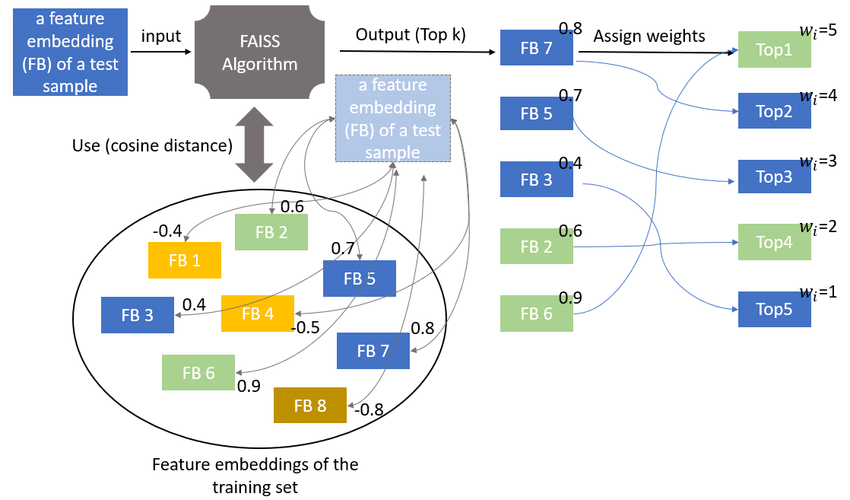
FAISS workflow
Alright, let’s now get practical. As I mentioned before, today we’re going to implement this algorithm on a set of texts - which means we’ll be searching for texts that are similar to each other.
The codes are available under an open-source license on GitHub.
To get started, I recommend creating a virtual environment for your project using tools like pip, conda, poetry, etc. Next, install the necessary libraries, which in this case will be:
sentence_transformers: Responsible for vectorizing our texts
faiss: Responsible for vector search
Then, you can import the libraries, load your dataframe, and assign an incremental identification column, which can even be the index.
%pip install faiss-gpu -UqqNote: you may need to restart the kernel to use updated packages.from sentence_transformers import SentenceTransformer
from sentence_transformers import InputExample
import pandas as pd
import numpy as np
import faiss
import torch
df = pd.read_csv('./assets/similarity_search.csv')[['text', 'id']]
if len(df) != 0:
print(f'Dataset imported succcesfully with a shape of {df.shape} 🎉')
if df.id.min() > 0:
df.id = df.id.apply(lambda x: x - 1)
else:
print('ID Starting with zero!')
df.head(5)Dataset imported succcesfully with a shape of (280, 2) 🎉| text | id | |
|---|---|---|
| 0 | The COVID-19 pandemic has had a significant im... | 0 |
| 1 | Artificial intelligence is transforming variou... | 1 |
| 2 | Social media platforms play a crucial role in ... | 2 |
| 3 | Renewable energy sources like solar and wind p... | 3 |
| 4 | Cryptocurrencies such as Bitcoin have gained w... | 4 |
Now that we have our data, let’s instantiate our vectorization model using SentenceTransformer. It takes the model’s name as an argument, the device being used, or a cache directory.
The model’s name is the only mandatory argument, and you can find it on the Hugging Face model hub if you’re unsure which one to choose. The device used is important because if you’re working with large volumes or vector operations, a GPU can be beneficial, and the cache directory is used to store model information to avoid downloading it every time you call it.
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print(f'Using the {str.upper(device)} device!')
model = SentenceTransformer(
'distilbert-base-nli-stsb-mean-tokens',
device = device,
cache_folder = './assets/cache/'
)Using the CUDA device!To test our vectorization model, let’s vectorize our first 5 texts. Note that the vectors, also called embeddings, have already been generated:
texts = df.text.values.tolist()
texts[:3]['The COVID-19 pandemic has had a significant impact on global economies.',
'Artificial intelligence is transforming various industries, including healthcare and finance.',
'Social media platforms play a crucial role in connecting people around the world.']embeddings = model.encode(texts)
embeddings[:3]array([[ 0.94750345, -1.0846483 , -0.22848324, ..., -0.06836035,
-0.14919858, 0.6607197 ],
[ 0.28361621, -0.14619698, 0.76421624, ..., -0.09583294,
-0.00354804, 0.03140309],
[ 0.0471359 , -0.09198052, 0.03990437, ..., -0.05552321,
-1.0880417 , -0.33173537]], dtype=float32)With that done, we are ready for the FAISS configuration that comes next.
First, let’s use our “id” column as the index and save this transformation in a variable, as in line 1. Next, we’ll create an index identifier that contains the values from the “id” column, which will serve as a mapping to the FAISS index’s indices - helping us associate the dataframe’s identifiers with the vector points.
As a next step, let’s normalize the vectors generated earlier using L2 normalization - preserving the relative direction between the vectors. In line 4, I made a copy to preserve the original array in case it’s needed later.
Finally, let’s create a FAISS index of type IndexFlatIP, which will be used to perform queries on the points using the inner product. The parameter defines the dimension of the space, and the choice of this index type was simply because it is efficient and common.
df_to_index = df.set_index(['id'], drop = False)
id_index = np.array(df_to_index.id.values).flatten().astype('int')
normalized_embeddings = embeddings.copy()
faiss.normalize_L2(normalized_embeddings)
index_flat = faiss.IndexFlatIP(len(embeddings[0]))Next, we’ll create an IndexIDMap object, which will be created from the index_flat and will allow us to associate identifiers with indexed vectors. This association is useful for retrieving specific information from the indexed vectors based on the identifiers.
To complete the FAISS configuration, we’ll add the normalized vectors and their corresponding identifiers to the IndexIDMap object, enabling queries and specific information retrieval.
index_content = faiss.IndexIDMap(index_flat)
index_content.add_with_ids(normalized_embeddings, id_index)Indeed, when it comes to vector search, data must be prepared to match the FAISS standard before conducting searches. This also involves formatting and organizing the output for a final delivery. Preprocessing and post-processing steps are essential to ensure the effectiveness and usability of vector search systems.
With this, we define a function that will take care of these steps for us. As parameters, I’ve defined query for the search texts/terms and k for the number of results we want.
First, we vectorize our text using SentenceTransformer, and then we normalize it using the FAISS normalizer itself, as shown in lines 2 and 3. Now, we search for the top-k results similar to our query term, as demonstrated in line 5.
The identifiers and similarities are then extracted from the result stored in top_k, and a message with the search text is printed on the screen, as seen in lines 6 and 7. Finally, in lines 11 and 12, the results are obtained from the dataframe that had the identifiers transformed into indices, and a new column corresponding to the similarities of the points found with the query is added.
In conclusion, the results are returned as a new dataframe with redefined indices, discarding the previous ones.
def search(query: str, k: int = 5) -> pd.core.frame.DataFrame:
vector = model.encode([query])
faiss.normalize_L2(vector)
top_k = index_content.search(vector, k)
ids = top_k[1][0].tolist()
similarities = top_k[0][0].tolist()
print(f'Searching for "{query}"...')
results = df_to_index.loc[ids]
results['similarity'] = similarities
output = results.reset_index(drop = True)[['id', 'text', 'similarity']]
return outputLet’s see it in practice. Below, I conducted three different searches with different numbers of returns. Let’s see how it behaved.
search('What am I thinking? I love cars', 3)Searching for "What am I thinking? I love cars"...| id | text | similarity | |
|---|---|---|---|
| 0 | 6 | Self-driving cars have the potential to enhanc... | 0.456869 |
| 1 | 91 | The ethical considerations of AI-powered auton... | 0.395022 |
| 2 | 228 | The use of AI in personalized entertainment re... | 0.382918 |
search('Biology is interesting, send me 5 related topics please', 5)Searching for "Biology is interesting, send me 5 related topics please"...| id | text | similarity | |
|---|---|---|---|
| 0 | 67 | The exploration of deep-sea ecosystems reveals... | 0.528142 |
| 1 | 160 | Advancements in bioinformatics enable faster a... | 0.474495 |
| 2 | 38 | Ethical considerations in gene editing and clo... | 0.464431 |
| 3 | 64 | The ethical implications of gene editing and C... | 0.449795 |
| 4 | 132 | The potential of bioprinting technology in reg... | 0.427724 |
search('Can you suggest me something about Deep Learning?', 6)Searching for "Can you suggest me something about Deep Learning?"...| id | text | similarity | |
|---|---|---|---|
| 0 | 255 | The challenges of interpretability in deep lea... | 0.564732 |
| 1 | 197 | Advancements in quantum machine learning algor... | 0.487619 |
| 2 | 184 | The integration of AI in education transforms ... | 0.471418 |
| 3 | 113 | The potential of quantum sensors opens up new ... | 0.467105 |
| 4 | 106 | The role of AI in personalized education and a... | 0.454311 |
| 5 | 137 | The potential of 3D bioprinting in tissue engi... | 0.447400 |
We have explored the FAISS tool and seen that it offers various indexing methods that enable fast and accurate searches, making it applicable in various domains. We demonstrated practical implementation on a set of texts, but we know that vector search can be applied to any type of data source as long as vectorization is possible.
FAISS stands out for its ability to handle high-dimensional spaces, so remember that our implementation was just a test and usage example. Its flexibility and performance make it a promising option, and its use in conjunction with vectorization techniques, such as SentenceTransformer, can bring significant benefits in terms of efficiency and accuracy.
Below, I provide the link to the GitHub repository with the project and the data used, as well as to the official website and documentation.
| References |
|---|
| Github repository |
| FAISS official webpage |
| FAISS documentation |
Thanks for reading, I’ll see you in the next one ⭐