%pip install -Uqq loguru fastai duckduckgo_searchNote: you may need to restart the kernel to use updated packages.You may have heard about Computer Vision before - that refers to a field of Artificial Intelligence that trains computers to interpret and understand the visual world. It enables computers to derive information from images, videos, and other inputs. Today we’ll dive in the practical manner in a high level by classifying images and using Fast AI, a library built on top of Pytorch.
To classify images, I will not be using vanilla PyTorch or TensorFlow. Instead, I will introduce the amazing library from FastAI, which makes deep learning more accessible. The goal is to accomplish a task to understand the capabilities of computers today and generate enough interest to dive deeper into the subject. For that, we’ll be classifying whether an image is a watermelon or a strawberry.
I am currently using an NVIDIA RTX A6000 GPU, but I believe it can also be accomplished with a less powerful GPU. It is recommended to run this task on a GPU rather than a CPU, though.
So, without any more further ado, let’s start by downloading some libraries and importing them:
%pip install -Uqq loguru fastai duckduckgo_searchNote: you may need to restart the kernel to use updated packages.from fastdownload import download_url
from duckduckgo_search import DDGS
from fastai.vision.all import *
from fastcore.all import *
from loguru import logger
from time import sleep
import fastcore
import warnings
import socket
warnings.filterwarnings("ignore")
try:
socket.setdefaulttimeout(1)
socket.socket(socket.AF_INET, socket.SOCK_STREAM).connect(('1.1.1.1', 53))
logger.success('Socket configured ✔')
except socket.error as ex:
raise Exception('No internet connection...')2023-09-09 15:28:41.891 | SUCCESS | __main__:<module>:16 - Socket configured ✔Below, you can find the description of each library installed.
Another important thing to mention is the try/except part on this setup. It is important because it performs a simple check to determine if the host has internet connectivity before proceeding with further execution of the program. This is vital as I’ll be downloading images later.
So, in order to train a model, we’ll need some data so it can learn from them, as this is a supervised learning problem. I’ll be creating a function to search for images and returning an L type.
An
Ltype is is a function that converts a regular Python list into a fastai list, offering extra functionality compared to a regular list, such as filtering and mapping
def search_images(keyword: str, max: int = 50) -> fastcore.foundation.L:
print(f'{max} images of {keyword} coming...')
return L(DDGS().images(keyword, safesearch='On')).itemgot('image')[:max]Let’s now try downloading a strawberry and a watermelon photo and check if our function was correctly implemented.
urls = search_images(keyword = 'strawberry', max = 3)
destination = './assets/strawberry/strawberry.jpg'
download_url(urls[0], destination, show_progress=False)
img = Image.open(destination)
img.to_thumb(256, 256)3 images of strawberry coming...
urls = search_images(keyword = 'watermelon', max = 10)
destination = './assets/watermelon/watermelon.jpg'
download_url(urls[6], destination, show_progress=False)
img = Image.open(destination)
img.to_thumb(256, 256)10 images of watermelon coming...
Awesome, now let’s properly download these images in a greater amount and in two diferent folder - these folder will be the class names later on.
Note that I used a sleep of 5 second, so I don’t get request troubles.
searches: tuple = 'strawberry', 'watermelon'
path = Path('./assets')
for search in searches:
destination = (path/search)
destination.mkdir(exist_ok = True, parents = True)
download_images(destination, urls = search_images(f'{search} photos'))
sleep(5)
download_images(destination, urls = search_images(f'{search} black and white'))
sleep(5)
download_images(destination, urls = search_images(f'{search} cartoon'))
sleep(5)
download_images(destination, urls = search_images(f'{search} AI'))
sleep(5)
resize_images(path/search, max_size = 400, dest = path/search)50 images of strawberry photos coming...
50 images of strawberry black and white coming...
50 images of strawberry cartoon coming...
50 images of strawberry AI coming...
50 images of watermelon photos coming...
50 images of watermelon black and white coming...
50 images of watermelon cartoon coming...
50 images of watermelon AI coming...Let’s also ensure that all our images are valid, so I’ll make a quick check and unlink the broken ones.
failed = verify_images(get_image_files(path))
failed.map(Path.unlink)
if len(failed) > 0:
print(f'There were {len(failed)} failed images.')
else:
print('There were no failed images.')There were 4 failed images.
Now that we have the images downloaded, let’s use a DataBlock to define the data processing pipeline for creating data loaders - that are important for several key reasons including: efficient data loading, batching, data augmentation, shuffling, paralellism etc.
dls = DataBlock(
blocks = (ImageBlock, CategoryBlock),
get_items = get_image_files,
splitter = RandomSplitter(valid_pct = 0.2, seed = 20),
get_y = parent_label,
item_tfms = [Resize(192, method = 'squish')]
).dataloaders(path, bs = 32)
dls.show_batch(max_n = 6)
Alright, so far we have downloaded our images and created our dataloader. Now it’s time to train our model and, for that, we’ll see how simplified it is to use Fast AI.
learn = vision_learner(dls, resnet18, metrics = [error_rate, accuracy])
learn.fine_tune(15)| epoch | train_loss | valid_loss | error_rate | accuracy | time |
|---|---|---|---|---|---|
| 0 | 0.575720 | 0.110310 | 0.034483 | 0.965517 | 00:04 |
| epoch | train_loss | valid_loss | error_rate | accuracy | time |
|---|---|---|---|---|---|
| 0 | 0.115316 | 0.086936 | 0.025862 | 0.974138 | 00:03 |
| 1 | 0.065104 | 0.045375 | 0.021552 | 0.978448 | 00:02 |
| 2 | 0.055632 | 0.150614 | 0.030172 | 0.969828 | 00:03 |
| 3 | 0.071165 | 0.094440 | 0.030172 | 0.969828 | 00:03 |
| 4 | 0.070642 | 0.131956 | 0.017241 | 0.982759 | 00:02 |
| 5 | 0.052290 | 0.057936 | 0.017241 | 0.982759 | 00:03 |
| 6 | 0.046295 | 0.045453 | 0.017241 | 0.982759 | 00:03 |
| 7 | 0.045184 | 0.042271 | 0.017241 | 0.982759 | 00:02 |
| 8 | 0.043151 | 0.054159 | 0.034483 | 0.965517 | 00:02 |
| 9 | 0.035403 | 0.045328 | 0.021552 | 0.978448 | 00:02 |
| 10 | 0.029595 | 0.028453 | 0.017241 | 0.982759 | 00:03 |
| 11 | 0.022235 | 0.046433 | 0.017241 | 0.982759 | 00:02 |
| 12 | 0.017884 | 0.039667 | 0.017241 | 0.982759 | 00:03 |
| 13 | 0.017663 | 0.032925 | 0.017241 | 0.982759 | 00:03 |
| 14 | 0.020569 | 0.036629 | 0.017241 | 0.982759 | 00:02 |
Finally we have our model trained to recognize images and say whether it’s a strawberry or watermelon picture. Let’s go through some visualizations on its performance by viewing the confusion matrix, the classification report and a loss plot.
interp = ClassificationInterpretation.from_learner(learn)
losses,idxs = interp.top_losses()
assert len(dls.valid_ds)==len(losses)==len(idxs)
interp.plot_confusion_matrix(figsize=(4, 4.3), cmap='Reds')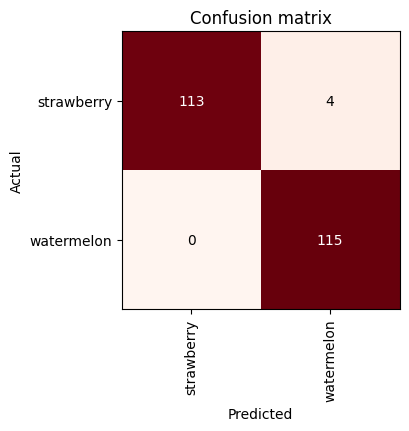
interp.print_classification_report() precision recall f1-score support
strawberry 1.00 0.97 0.98 117
watermelon 0.97 1.00 0.98 115
accuracy 0.98 232
macro avg 0.98 0.98 0.98 232
weighted avg 0.98 0.98 0.98 232
interp = ClassificationInterpretation.from_learner(learn)
losses, idxs = interp.top_losses()
assert len(dls.valid_ds) == len(losses) == len(idxs)
plt.figure(figsize=(4.5, 4.3))
plt.plot(losses[:20], c='#9a031e')
plt.title('Losses throughout the steps')
plt.xlabel('Step')
plt.ylabel('Loss')
plt.show()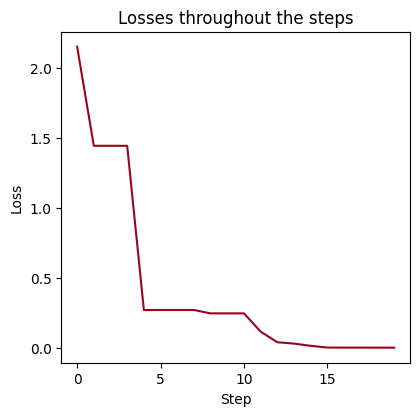
We’re getting to the end, as we’ve already developed a model that can differentiate images from two distinct fruits. Now I want to finish by downloading a test image that the model hasn’t seen before and even get the probabilities.
I’ll be choosing an image from Lexica Art and the image is as follow:
download_url(
'https://image.lexica.art/full_jpg/d814231d-332d-4569-84d7-820ff4742e38',
'./assets/test/test_image.jpg',
show_progress=False)
Image.open('./assets/test/test_image.jpg').to_thumb(256, 256)
category, _, probabilities = learn.predict(
PILImage.create('./assets/test/test_image.jpg')
)
print(f'PREDICTION REPORT:\n')
print(f'Category: {category}')
print(f'Probability: {torch.max(probabilities):.3f}')PREDICTION REPORT:
Category: strawberry
Probability: 1.000Thanks for reading, I’ll see you in the next one ⭐